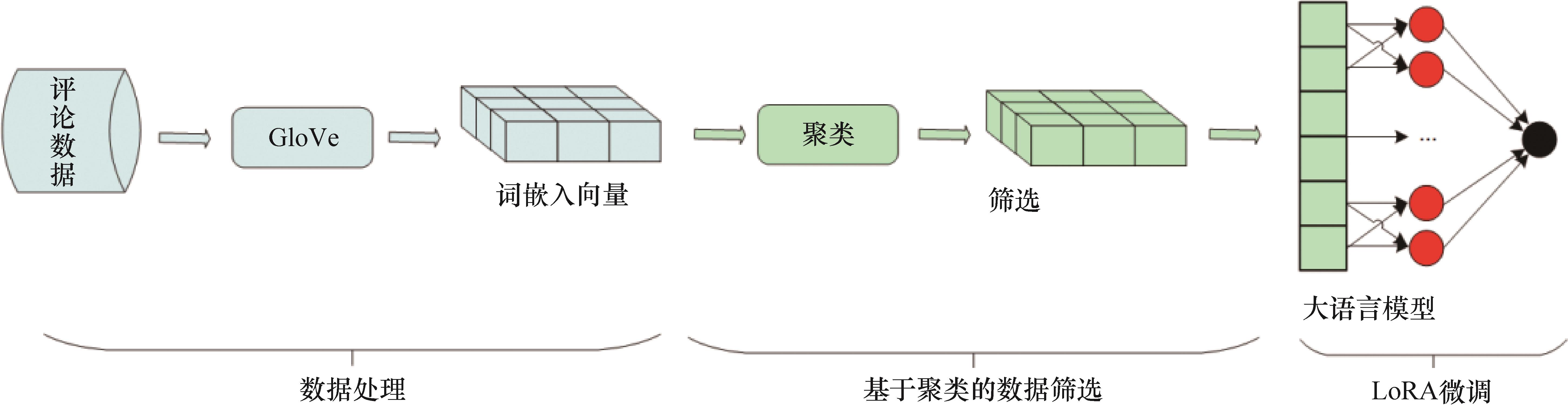
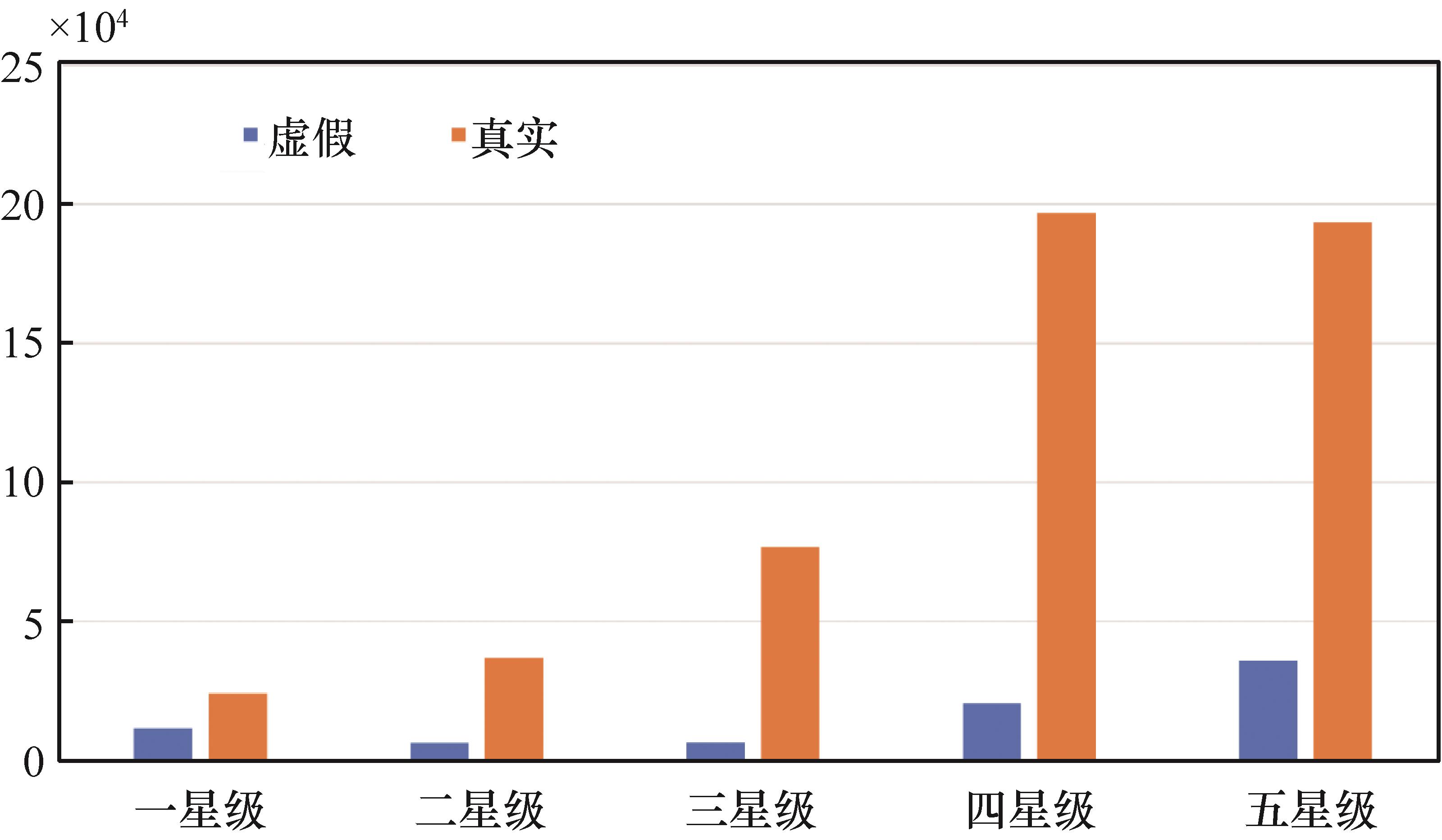
| [1] |
Paul H, Nikolaev A. Fake review detection on online E-commerce platforms: a systematic literature review[J]. Data Mining and Knowledge Discovery, 2021, 35(5): 1830-1881. DOI: 10.1007/s10618-021-00772-6 .
|
| [2] |
Gupta P, Gandhi S, Chakravarthi B R. Leveraging transfer learning techniques- BERT, RoBERTa, ALBERT and DistilBERT for fake review detection[C]//Proceedings of the 13th Annual Meeting of the Forum for Information Retrieval Evaluation. December 13 - 17, 2021, Virtual Event, India. ACM, 2021: 75-82. DOI: 10.1145/3503162.3503169 .
|
| [3] |
Mohawesh R, Xu S X, Tran S N, et al. Fake reviews detection: a survey[J]. IEEE Access, 2021, 9: 65771-65802. DOI: 10.1109/ACCESS.2021.3075573 .
|
| [4] |
Refaeli D, Hajek P. Detecting fake online reviews using fine-tuned BERT[C]//Proceedings of the 2021 5th International Conference on E-Business and Internet. October 15 - 17, 2021, Singapore, Singapore. ACM, 2021: 76-80. DOI: 10.1145/3497701.3497714 .
|
| [5] |
Hu B Z, Sheng Q, Cao J, et al. Bad actor, good advisor: exploring the role of large language models in fake news detection[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2024, 38(20): 22105-22113. DOI: 10.1609/aaai.v38i20.30214 .
|
| [6] |
Huang Y, Sun L, FakeGPT: fake news generation, explanation and detection of large language models[EB/OL].arXiv 2023:2310.05046.(2023-10-08)[2024-08-23]..
|
| [7] |
Ke J, Xu Z, Xu T,et al.An implicit semantic enhanced fine-grained fake news detection method based on large language models[J]. Journal of Computer Research and Development, 2024, 61(5): 1250-1260.DOI: 10.7544/issn1000-1239.202330967 .
|
| [8] |
Devlin J, Chang M, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol 1(Long and Short papers): 4171-4186.
|
| [9] |
Oliver M, Wang G. Crafting efficient fine-tuning strategies for large language models[EB/OL].arXiv 2023:2407.13906.(2023-07-18)[2024-08-23]..
|
| [10] |
Singh A, Pandey N. A study of optimizations for fine-tuning large language models[EB/OL].arXiv 2024:2406.02290.(2024-06-06)[2024-08-23]..
|
| [11] |
Duma R A, Niu Z D, Nyamawe A S, et al. Fake review detection techniques, issues, and future research directions: a literature review[J]. Knowledge and Information Systems, 2024, 66(9): 5071-5112. DOI: 10.1007/s10115-024-02118-2 .
|
| [12] |
Zhang D S, Zhou L N, Kehoe J L, et al. What online reviewer behaviors really matter? effects of verbal and nonverbal behaviors on detection of fake online reviews[J]. Journal of Management Information Systems, 2016, 33(2): 456-481. DOI:10.1080/07421222.2016.1205907 .
|
| [13] |
Casillo M, Colace F, Gupta B B, et al. Fake news detection using LDA topic modelling and K-nearest neighbor classifier[C]// Computational Data and Social Networks. Cham: Springer International Publishing, 2021: 330-339. DOI: 10.1007/978-3-030-91434-9_29 .
|
| [14] |
Kumar N, Venugopal D, Qiu L F, et al. Detecting review manipulation on online platforms with hierarchical supervised learning[J]. Journal of Management Information Systems, 2018, 35(1): 350-380. DOI:10.1080/07421222.2018.1440758 .
|
| [15] |
Zhang W, Zhang X, Chen J D, et al. Stacking GA2M for inherently interpretable fraudulent reviewer identification by fusing target and non-target features[J].International Journal of General Systems,2024,54(3):298-333. DOI:10.1080/03081079.2024.2384404 .
|
| [16] |
Du Q, Zong C, Zhang J. MoDS: model-oriented data selection for instruction tuning[EB/OL].arXiv 2023:2311.15653.(2023-11-27)[2024-08-22]..
|
| [17] |
Li M, Zhang Y, Li Z T, et al. From quantity to quality: boosting LLM performance with self-guided data selection for instruction tuning[C]//Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,2024,Vol 1: 7602-7635.DOI: 10.18653/v1/2024.naacl-long.421
|
| [18] |
Mehta V, Agarwal M, Kaliyar R K. A comprehensive and analytical review of text clustering techniques[J]. International Journal of Data Science and Analytics, 2024, 18(3): 239-258. DOI: 10.1007/s41060-024-00540-x .
|
| [19] |
Wang H, Zhou C D, Li L X. Design and application of a text clustering algorithm based on parallelized K-means clustering[J]. Revue D’ Intelligence Artificielle, 2019, 33(6): 453-460. DOI: 10.18280/ria.330608 .
|
| [20] |
Petukhova A, Matos-Carvalho J P, Fachada N. Text clustering with large language model embeddings[J]. International Journal of Cognitive Computing in Engineering, 2025, 6: 100-108. DOI: 10.1016/j.ijcce.2024.11.004 .
|
| [21] |
Ding N, Qin Y J, Yang G, et al. Parameter-efficient fine-tuning of large-scale pre-trained language models[J]. Nature Machine Intelligence, 2023, 5(3): 220-235. DOI: 10.1038/s42256-023-00626-4 .
|
| [22] |
Hu E J, Shen Y, Wallis P, et al. LoRA: low-rank adaptation of large language models[C]. ICLR 2022 Conference,2022,1912. .
|
| [23] |
Pennington J, Socher R, Manning C. Glove: global vectors for word representation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar. Stroudsburg, PA, USA: ACL, 2014: 1532-1543. DOI: 10.3115/v1/d14-1162 .
|
| [24] |
Hartigan J A, Wong M A. Algorithm AS 136: a K-means clustering algorithm[J]. Applied Statistics, 1979, 28(1): 100. DOI: 10.2307/2346830 .
|
| [25] |
Oyewole G J, Thopil G A. Data clustering: application and trends[J]. Artificial Intelligence Review, 2023, 56(7): 6439-6475. DOI: 10.1007/s10462-022-10325-y .
|
| [26] |
Upadhye A. A survey of text clustering techniques: algorithms, applications, and challenges[J]. International Journal of Science and Research (IJSR), 2021, 10(9): 1749-1752. DOI: 10.21275/sr24304163737 .
|
| [27] |
Rayana S, Akoglu L. Collective opinion Spam detection: bridging review networks and metadata[C]//Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Sydney NSW Australia. ACM, 2015: 985-994. DOI: 10.1145/2783258.2783370 .
|
| [28] |
Loshchilov I, Hutter F. Decoupled weight decay regularization[EB/OL]. arXiv 2017:1711.05101. (2017-11-14)[2024-08-22]. .
|
| [29] |
Liu Y, Ott M, Goyal N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL].arXiv 2019:1907.11692. (2019-07-26)[2024-08-23]..
|
| [30] |
Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16(1): 321-357. DOI: 10.5555/1622407.1622416 .
|
| [31] |
Parsaeimehr E, Fartash M, Akbari Torkestani J. Improving feature extraction using a hybrid of CNN and LSTM for entity identification[J]. Neural Processing Letters, 2023, 55(5): 5979-5994. DOI: 10.1007/s11063-022-11122-y .
|
 )
)