中国科学院大学学报 ›› 2026, Vol. 43 ›› Issue (1): 14-22.DOI: 10.7523/j.ucas.2024.026
吴慧桢, 张三国( )
)
Huizhen WU, Sanguo ZHANG()
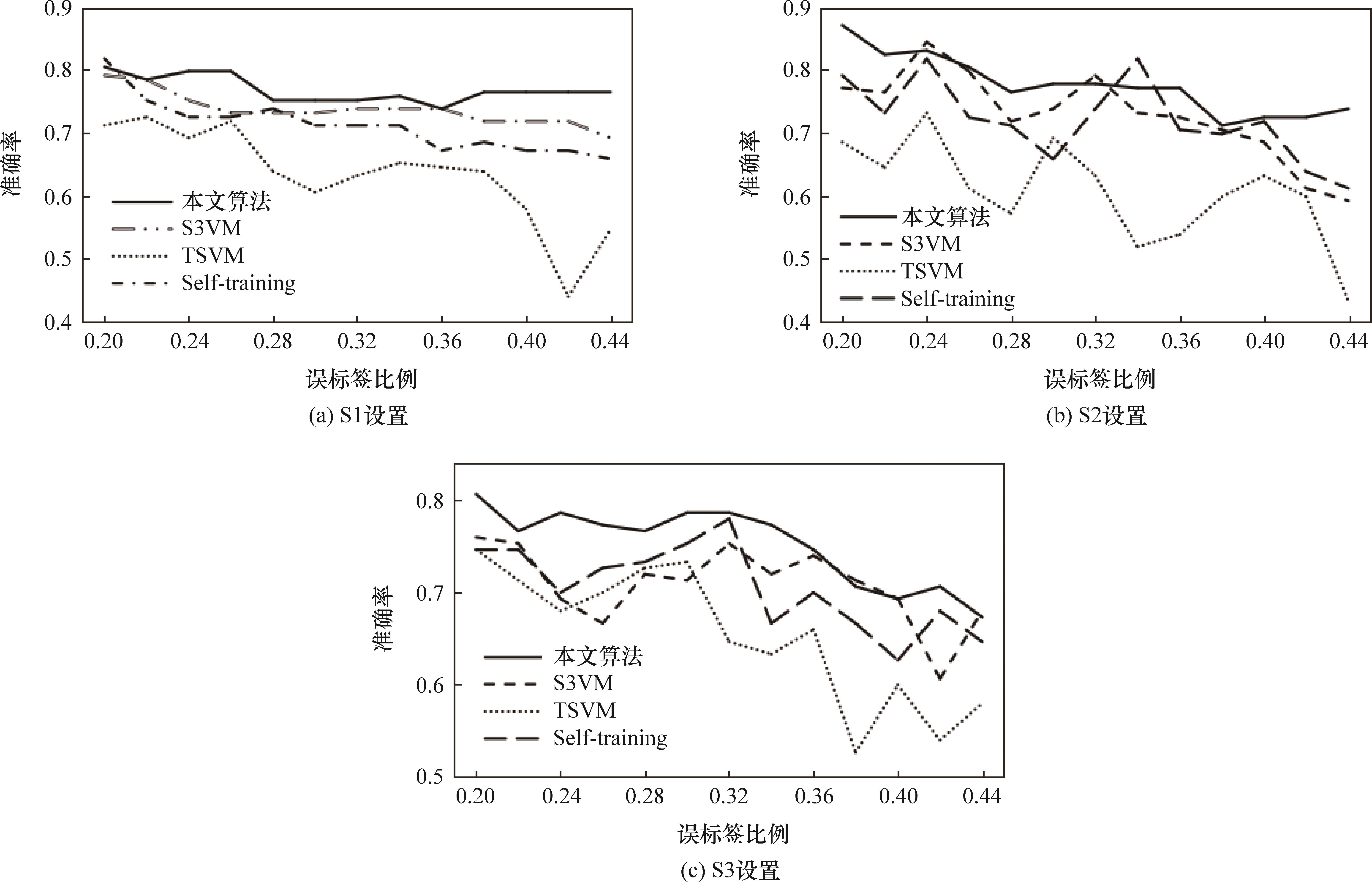
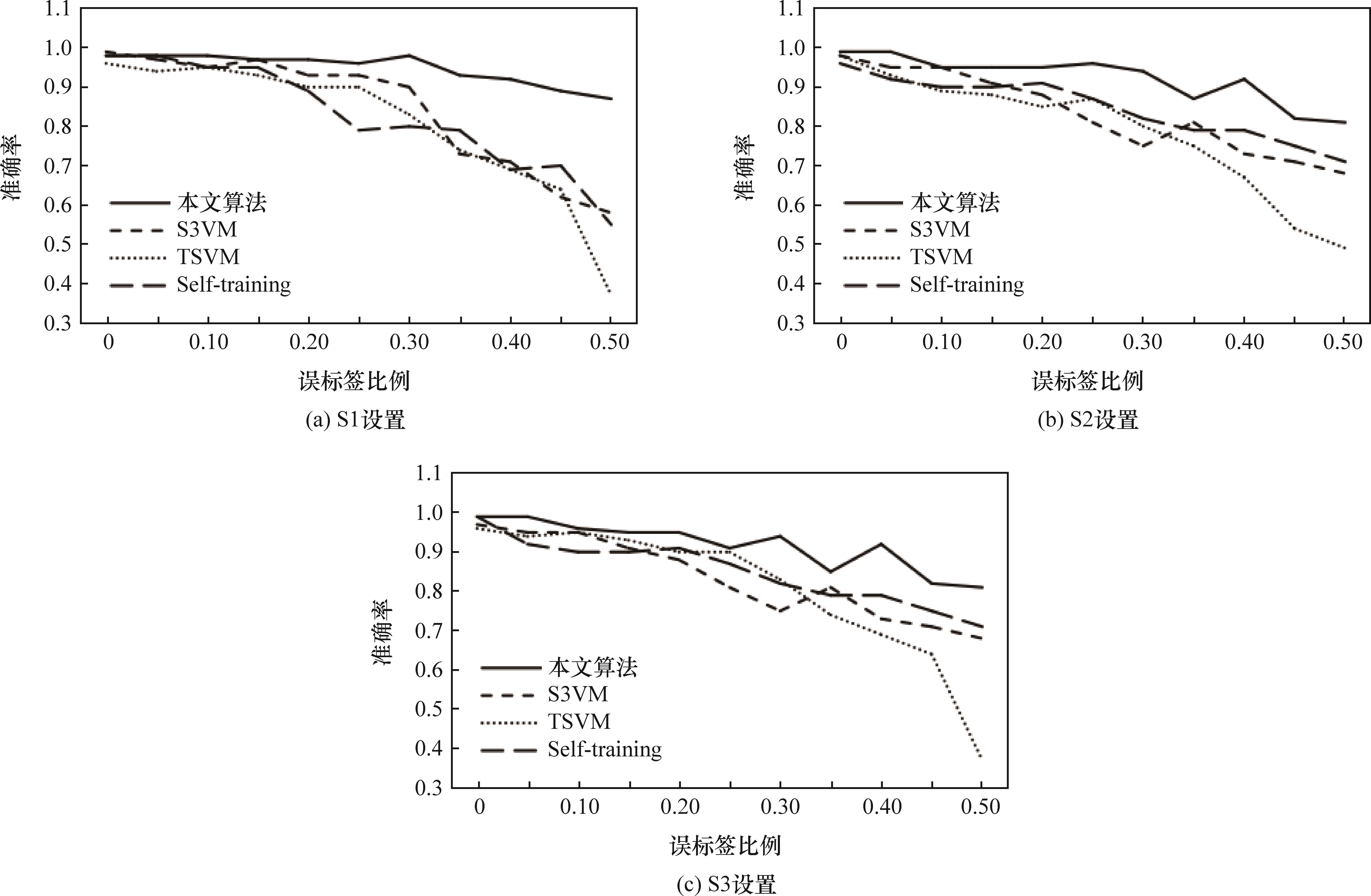
摘要:
提出一种基于模型平均与
中图分类号: